
Cohere For AI has announced the launch of Aya 23, a family of generative large language models (LLMs) featuring open weights for both 8-billion and 35-billion parameter versions.
Covering 23 languages which includes Arabic, Chinese (simplified & traditional), Czech, Dutch, English, French, German, Greek, Hebrew, Hindi, Indonesian, Italian, Japanese, Korean, Persian, Polish, Portuguese, Romanian, Russian, Spanish, Turkish, Ukrainian, and Vietnamese, Aya 23 aims to advance multilingual AI research significantly.
Click here to check out the model on Hugging Face.
Building on the success of the Aya initiative, which brought together 3,000 global collaborators to create the largest multilingual instruction fine-tuning dataset, Aya 23 shifts focus from breadth to depth. While Aya 101 spanned 101 languages, Aya 23 pairs a highly performant pre-trained model with the Aya dataset collection to deliver robust performance across 23 languages, reaching nearly half of the global population.
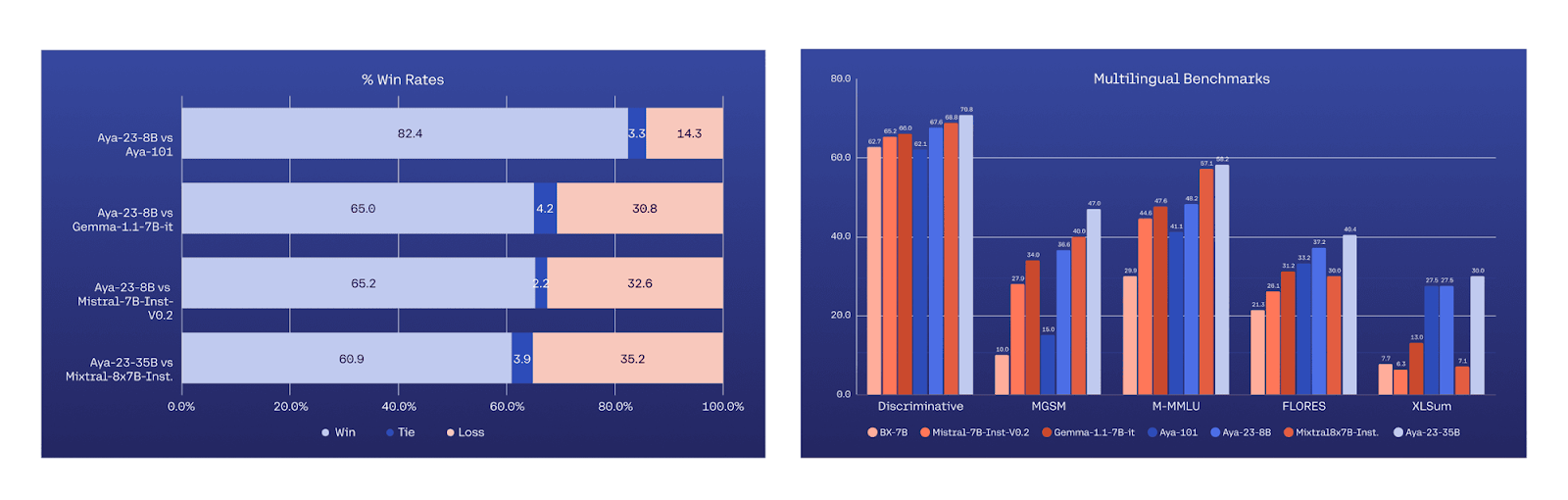
In benchmarking, the 35B parameter Aya 23 outperformed other massively multilingual open-source models and widely used open-weight instruction-tuned models, achieving top results across all covered languages.
The 8B parameter version also demonstrated best-in-class multilingual performance while maintaining efficiency and accessibility for developers, emphasising Cohere For AI’s dedication to democratising access to advanced technology.
Aya 23 is now available for experimentation, exploration, and foundational research, including safety auditing, on Hugging Face.
The post Cohere Releases Aya 23 Multilingual Models Including Hindi with 8 Bn and 35 Bn Parameters appeared first on AIM.